01
blind spot
Tested, Never Measured
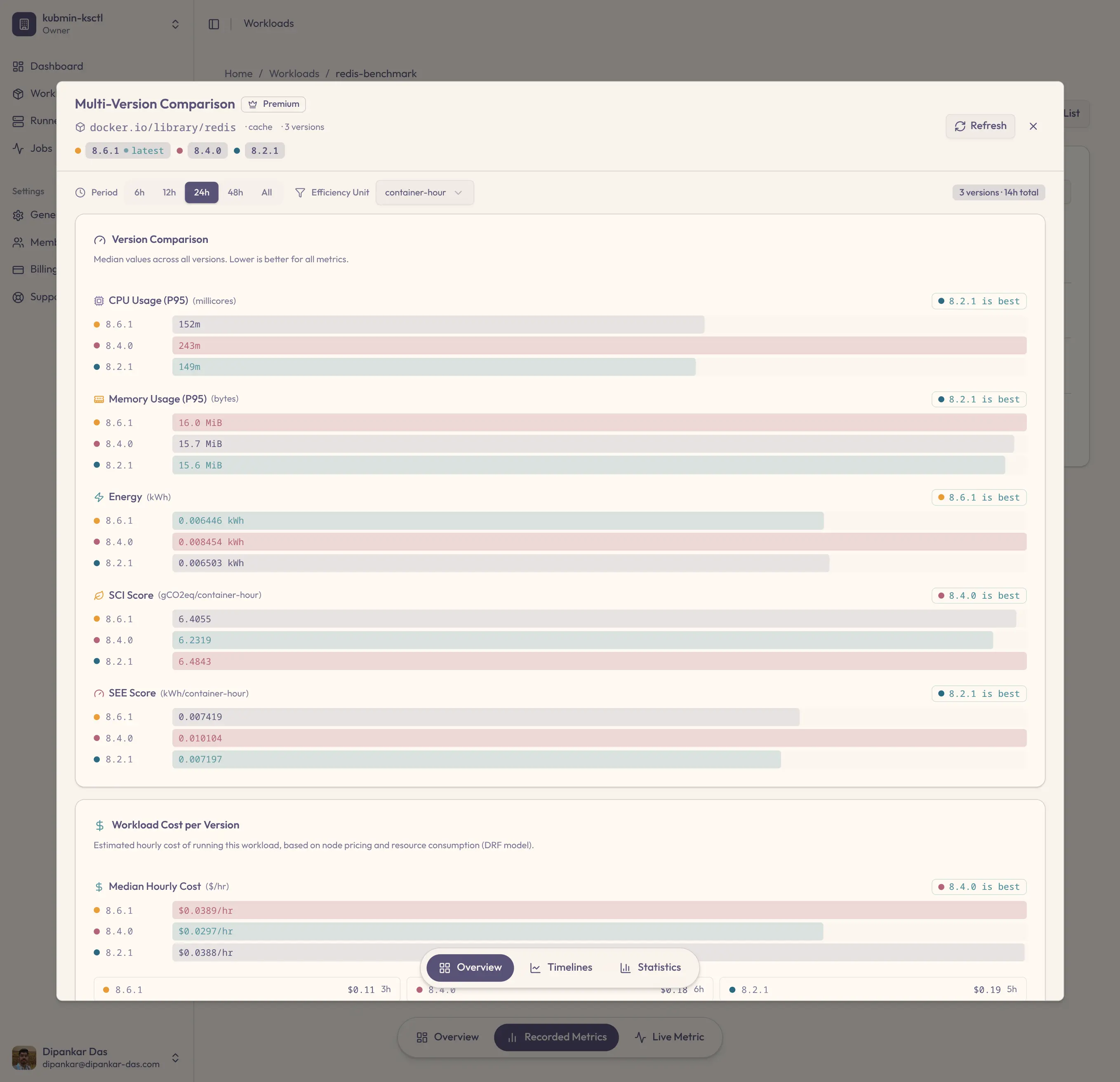
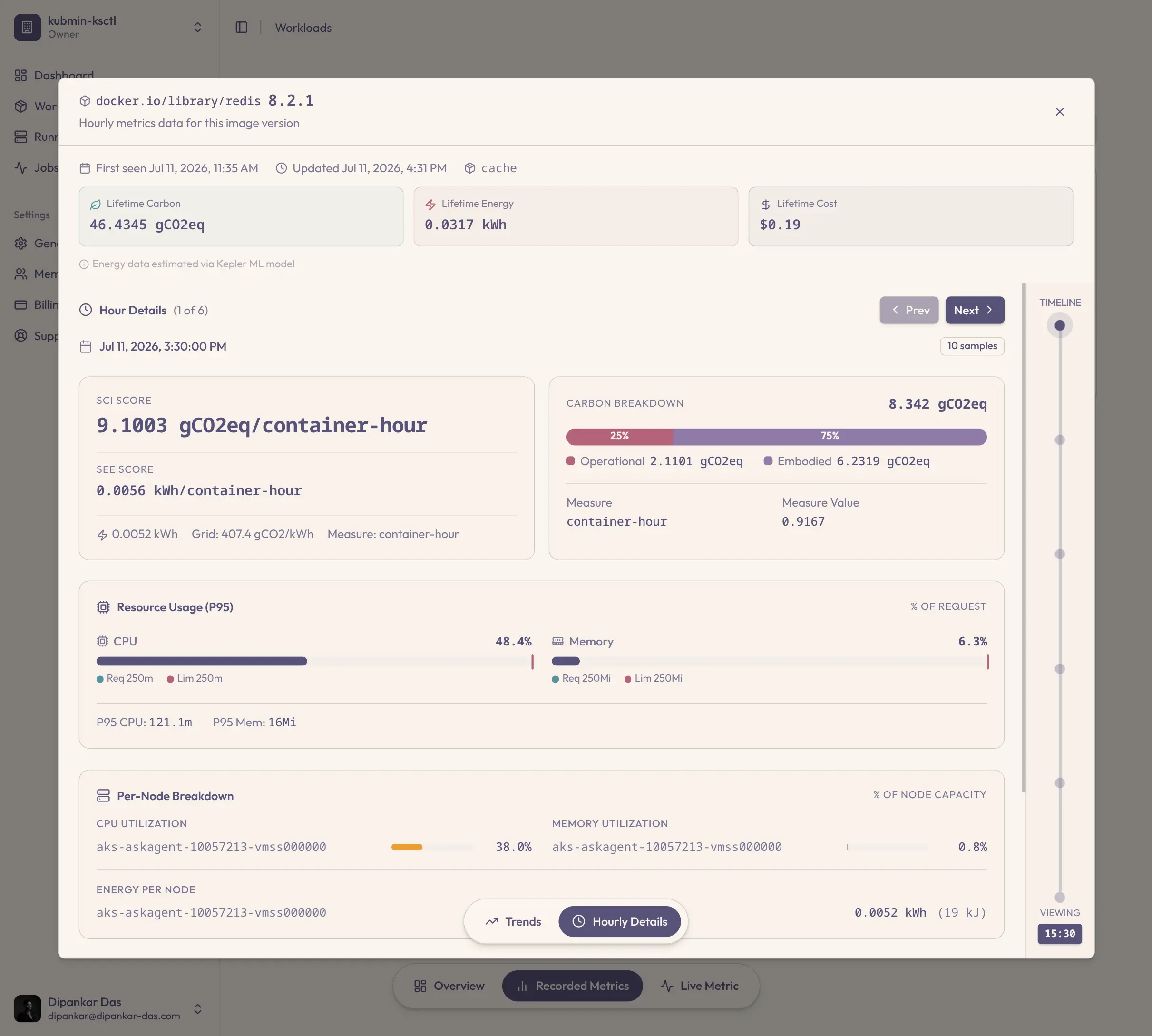
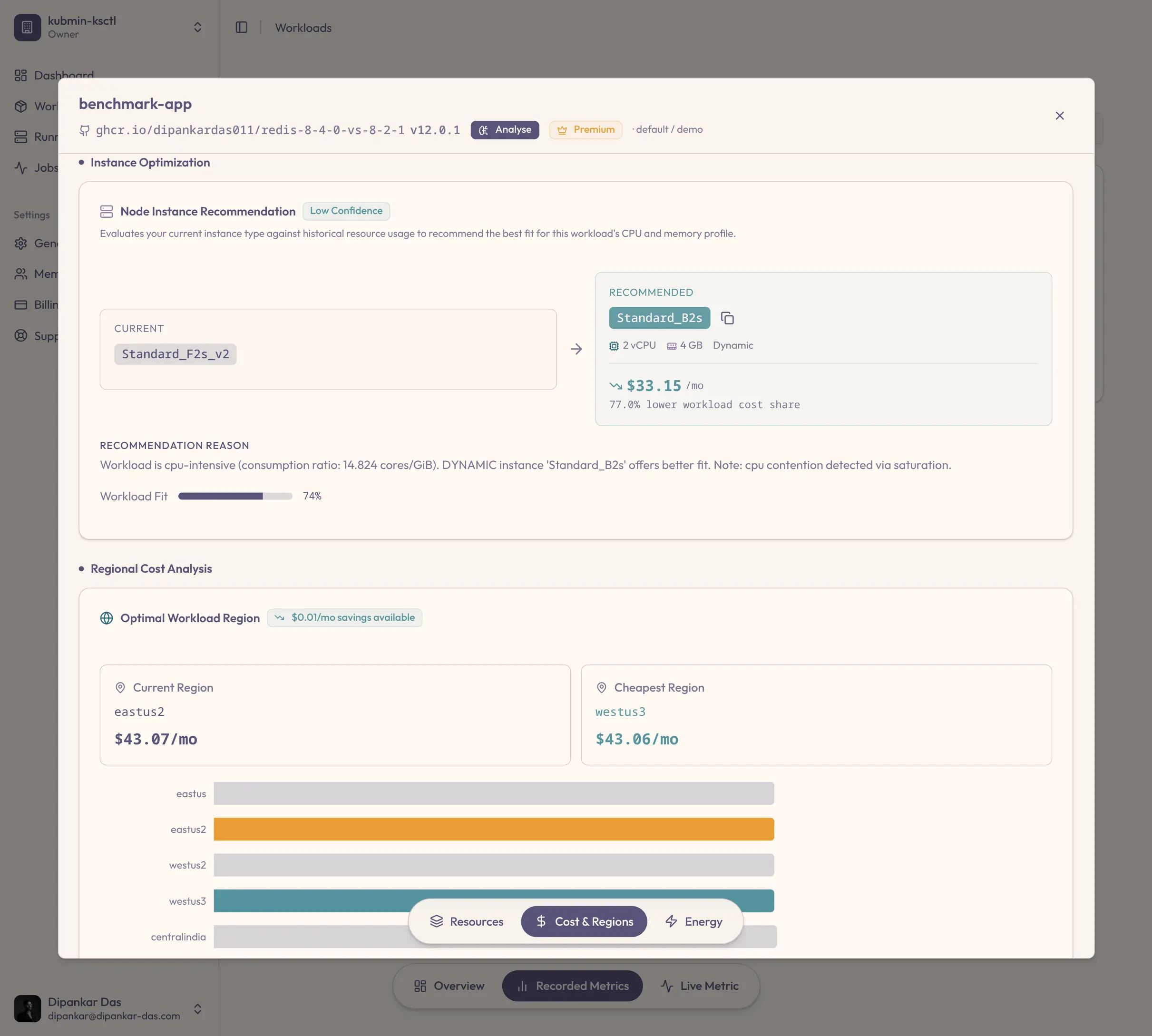
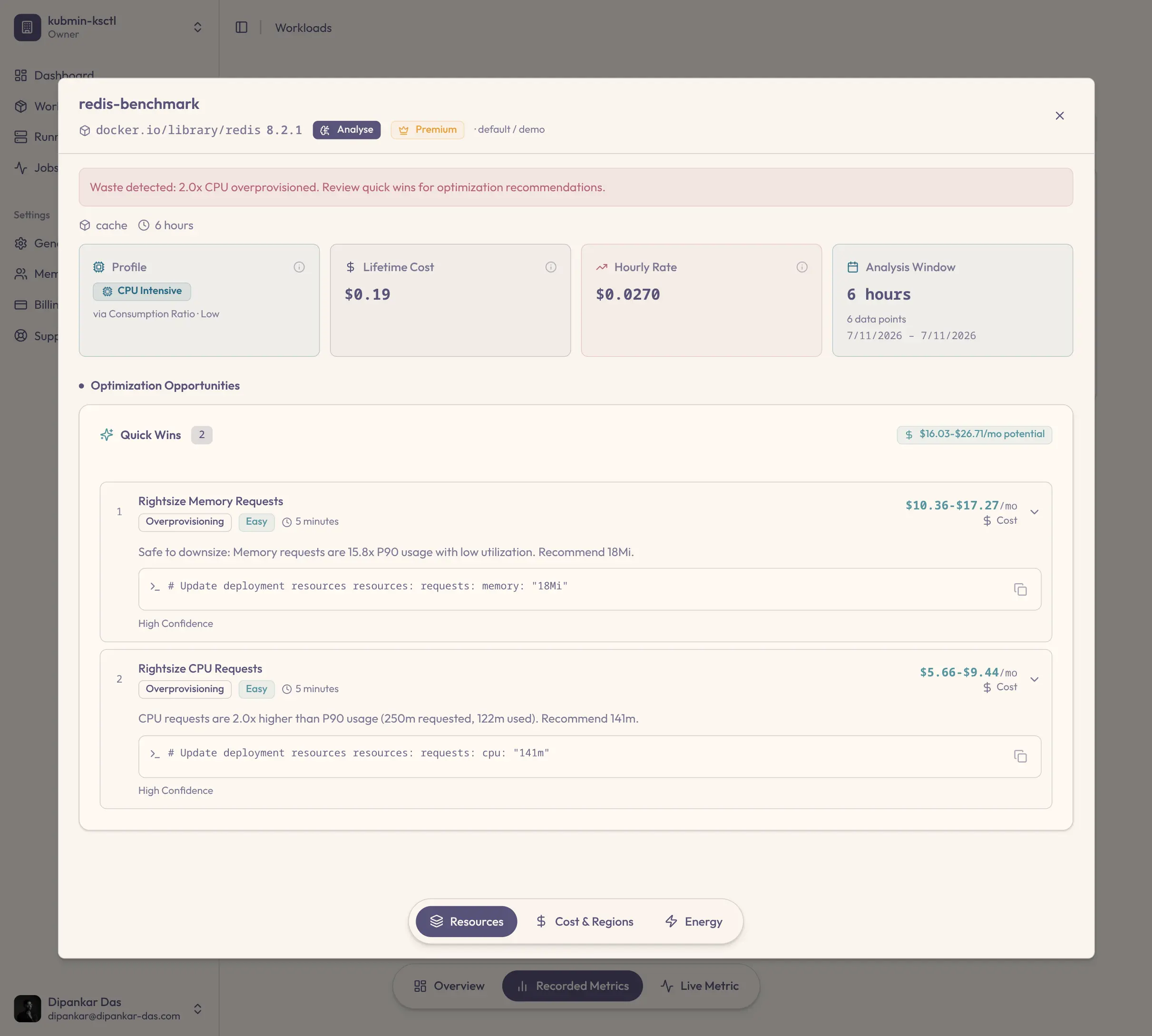
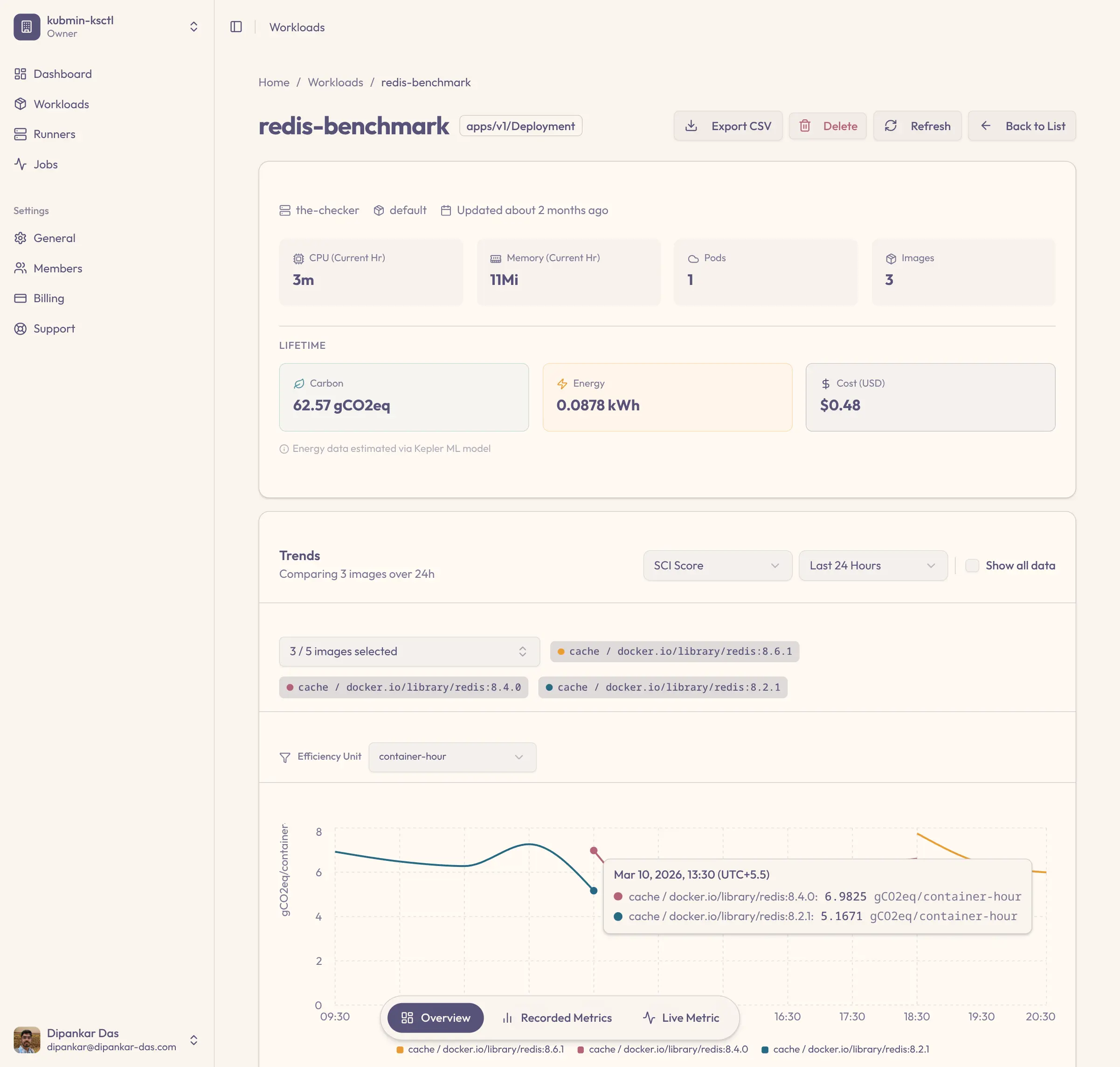
Unit tests, integration suites, even chaos drills — every release clears the pipeline. But no stage measures what that release consumes: CPU, memory, energy, money. Efficiency regressions ship behind green checkmarks, and the waste compounds with every deploy.